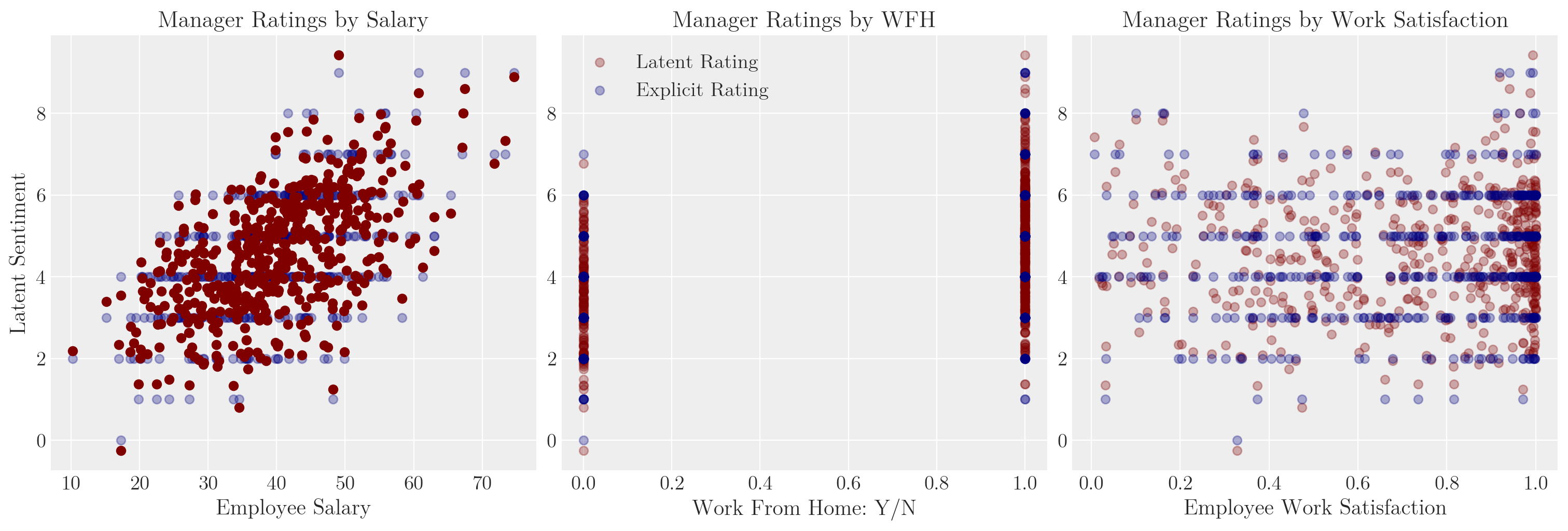
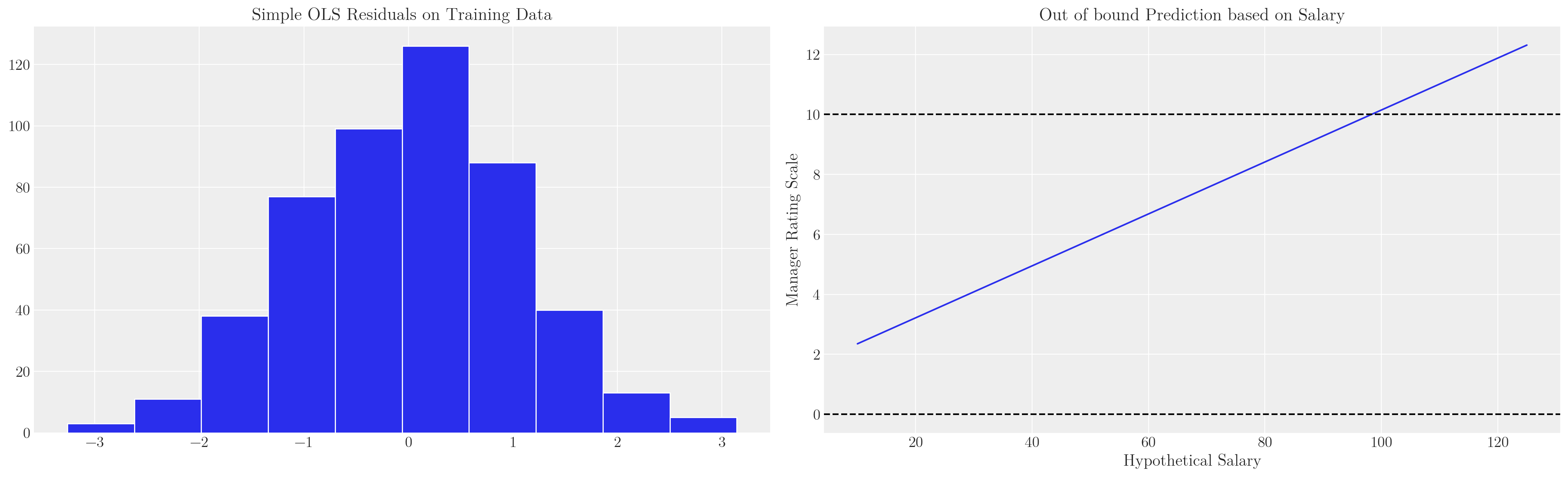
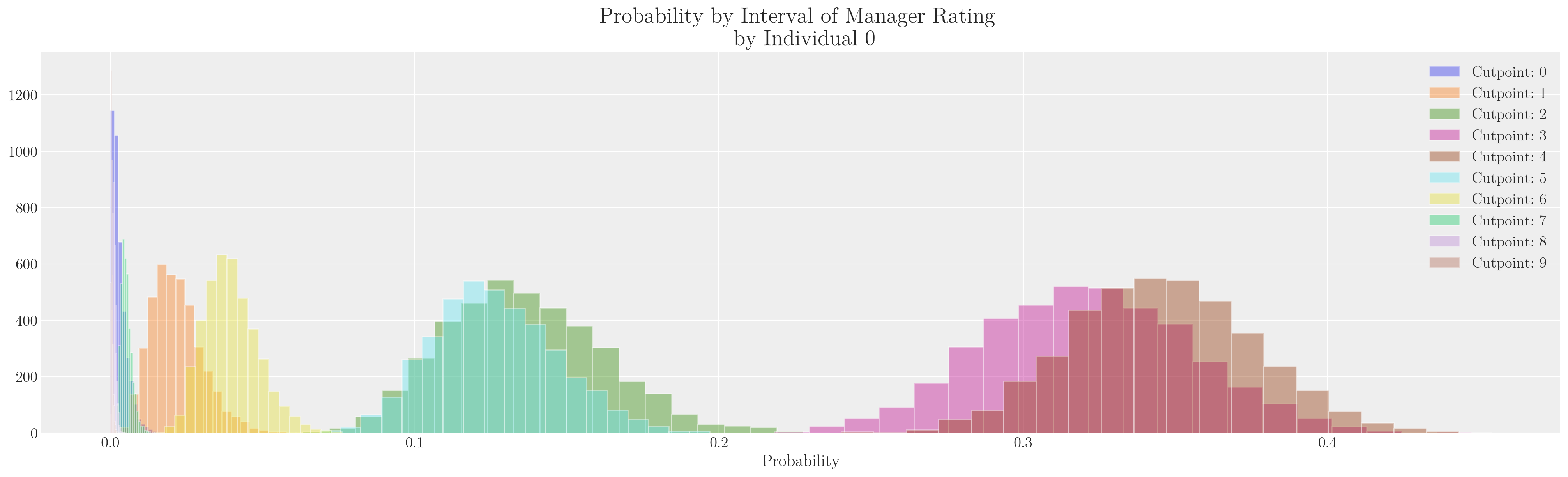
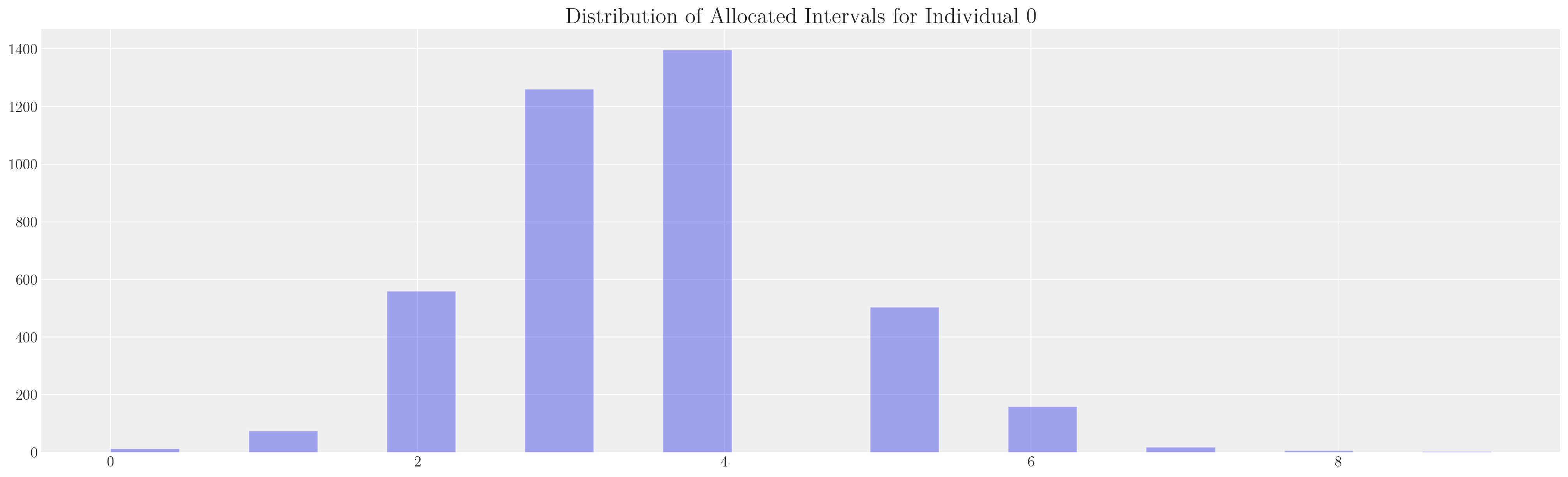
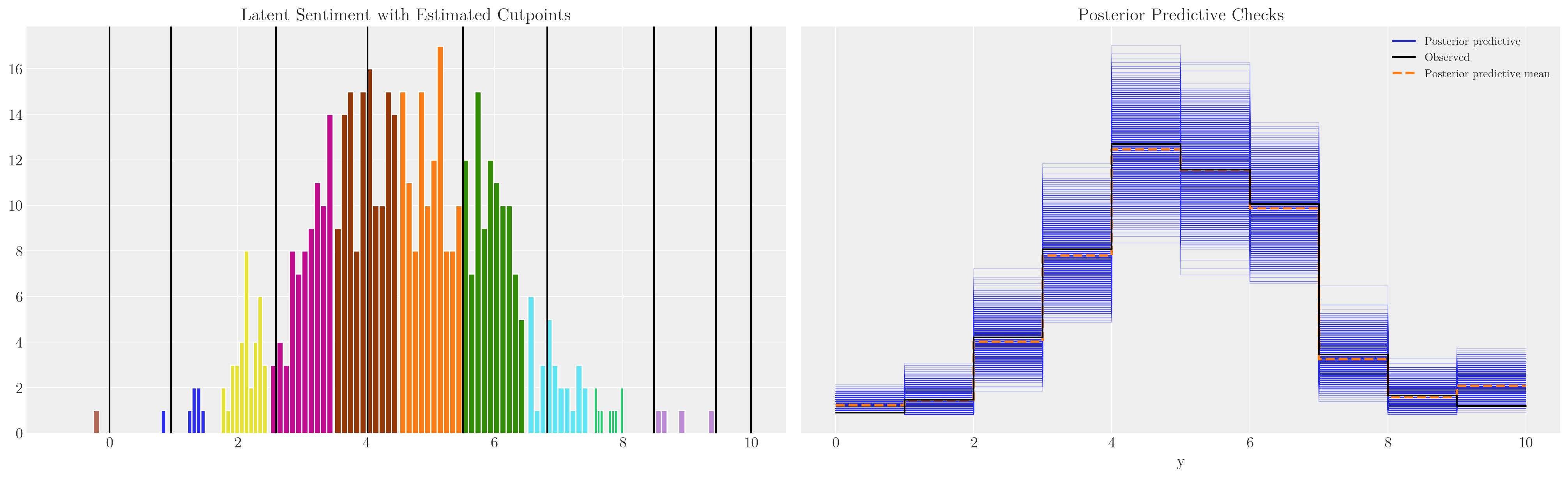
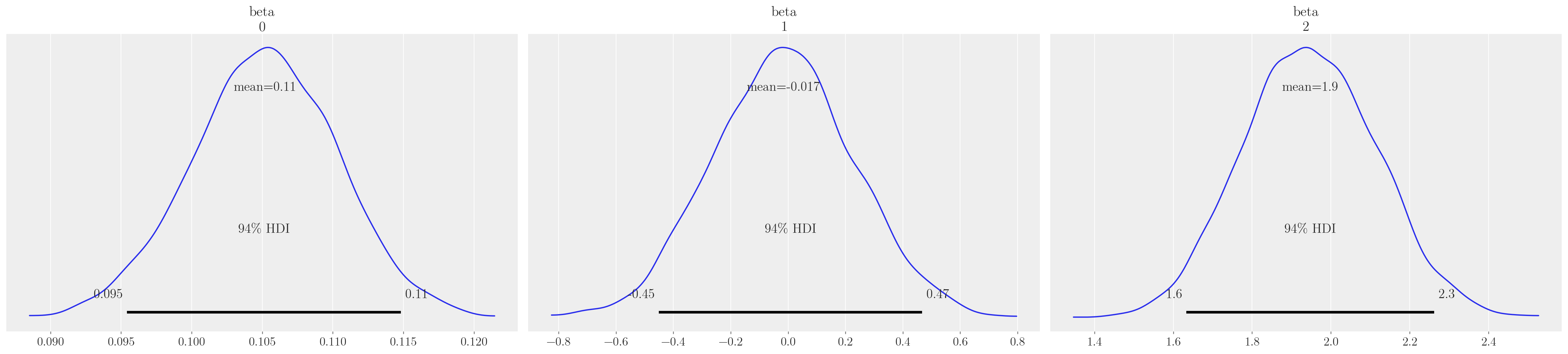
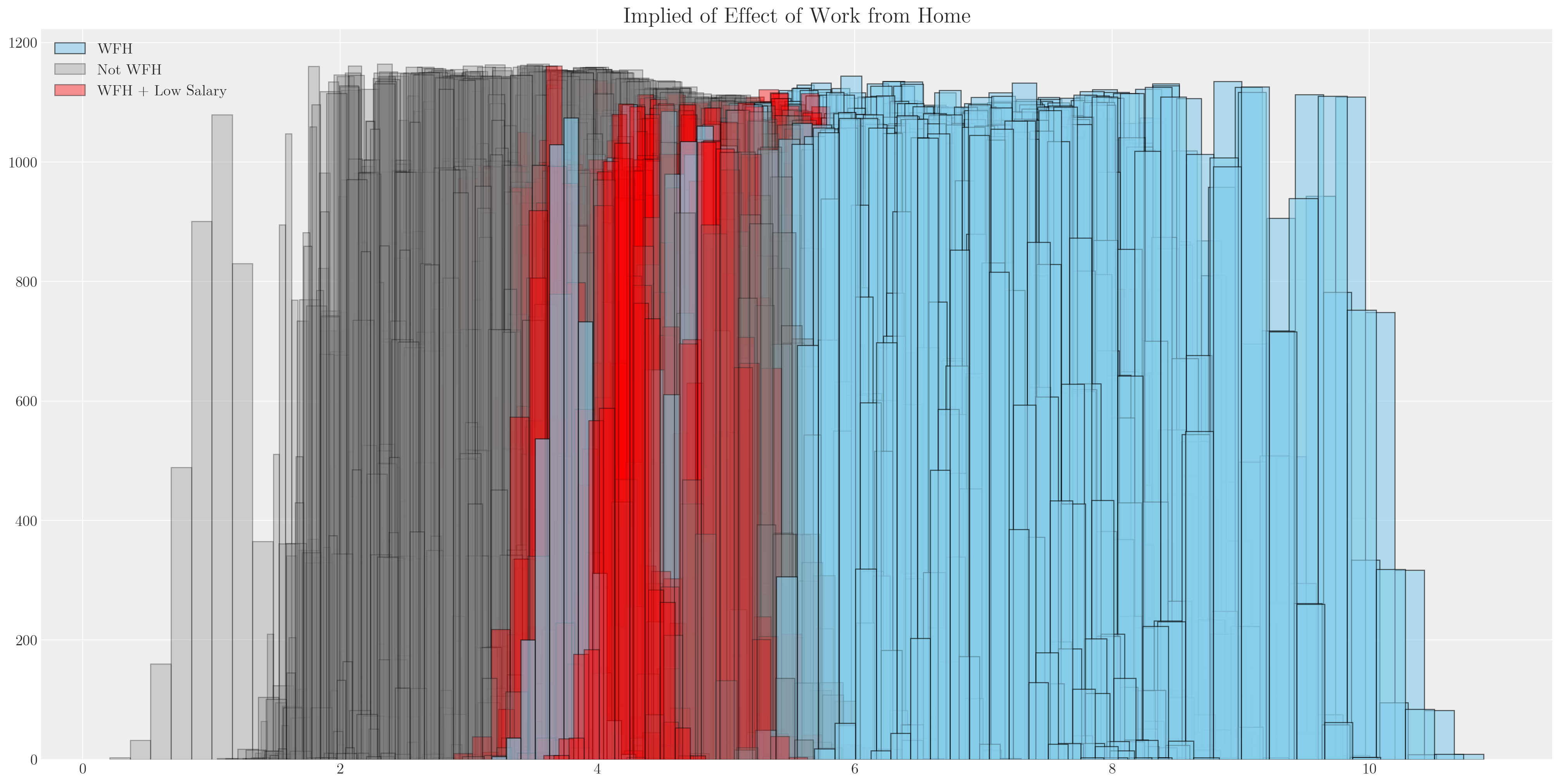
def make_model(priors, model_spec=1, constrained_uniform=False, logit=True):
with pm.Model() as model:
if constrained_uniform:
cutpoints = constrainedUniform(K, 0, K)
else:
sigma = pm.Exponential("sigma", priors["sigma"])
cutpoints = pm.Normal(
"cutpoints",
mu=priors["mu"],
sigma=sigma,
transform=pm.distributions.transforms.ordered,
)
if model_spec == 1:
beta = pm.Normal("beta", priors["beta"][0], priors["beta"][1], size=1)
mu = pm.Deterministic("mu", beta[0] * df.salary)
elif model_spec == 2:
beta = pm.Normal("beta", priors["beta"][0], priors["beta"][1], size=2)
mu = pm.Deterministic("mu", beta[0] * df.salary + beta[1] * df.work_sat)
elif model_spec == 3:
beta = pm.Normal("beta", priors["beta"][0], priors["beta"][1], size=3)
mu = pm.Deterministic(
"mu", beta[0] * df.salary + beta[1] * df.work_sat + beta[2] * df.work_from_home
)
if logit:
y_ = pm.OrderedLogistic("y", cutpoints=cutpoints, eta=mu, observed=df.explicit_rating)
else:
y_ = pm.OrderedProbit("y", cutpoints=cutpoints, eta=mu, observed=df.explicit_rating)
idata = pm.sample(nuts_sampler="numpyro", idata_kwargs={"log_likelihood": True})
idata.extend(pm.sample_posterior_predictive(idata))
return idata, model
priors = {"sigma": 1, "beta": [0, 1], "mu": np.linspace(0, K, K - 1)}
idata1, model1 = make_model(priors, model_spec=1)
idata2, model2 = make_model(priors, model_spec=2)
idata3, model3 = make_model(priors, model_spec=3)
idata4, model4 = make_model(priors, model_spec=3, constrained_uniform=True)
idata5, model5 = make_model(priors, model_spec=3, constrained_uniform=True)