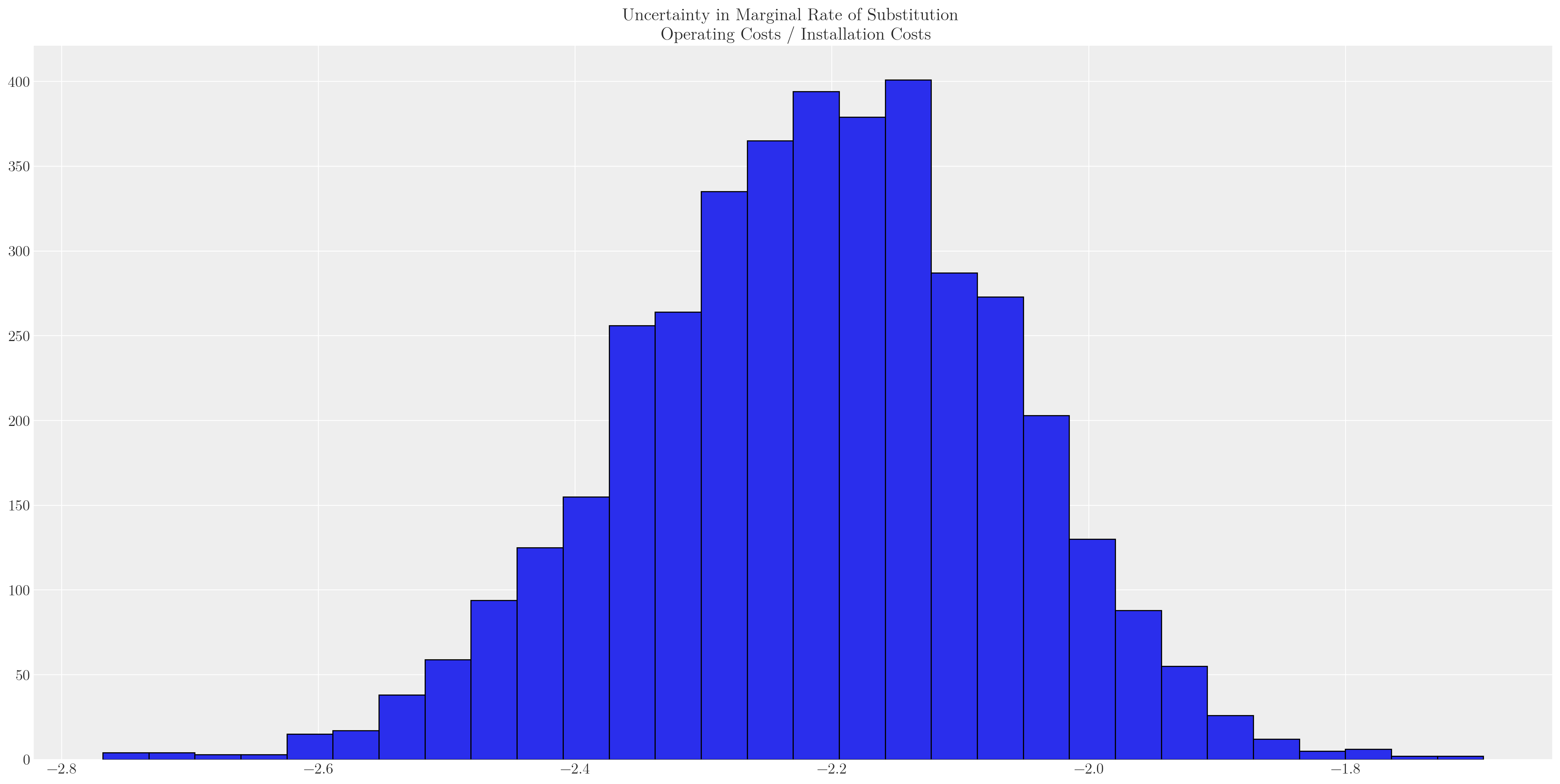
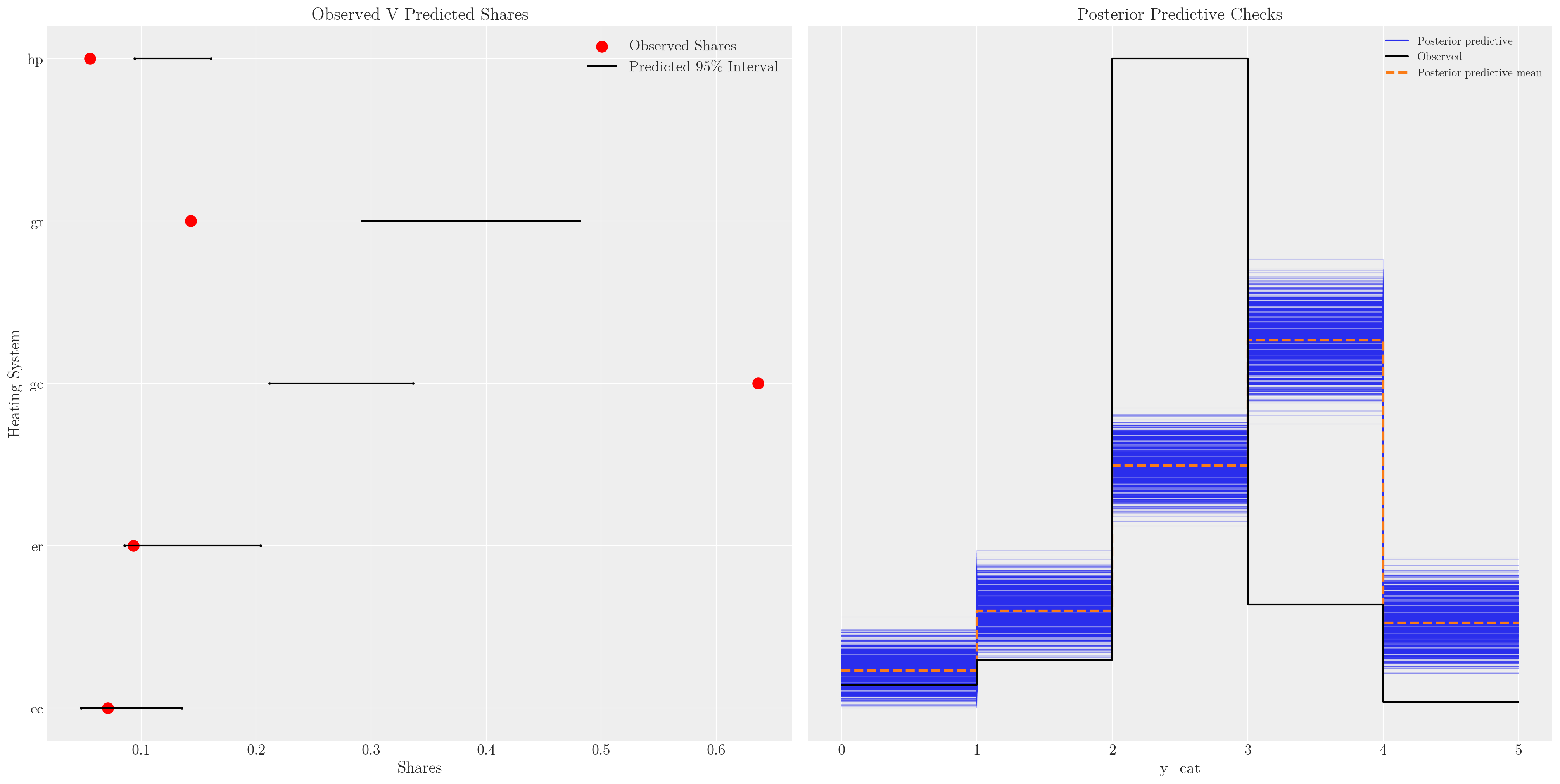
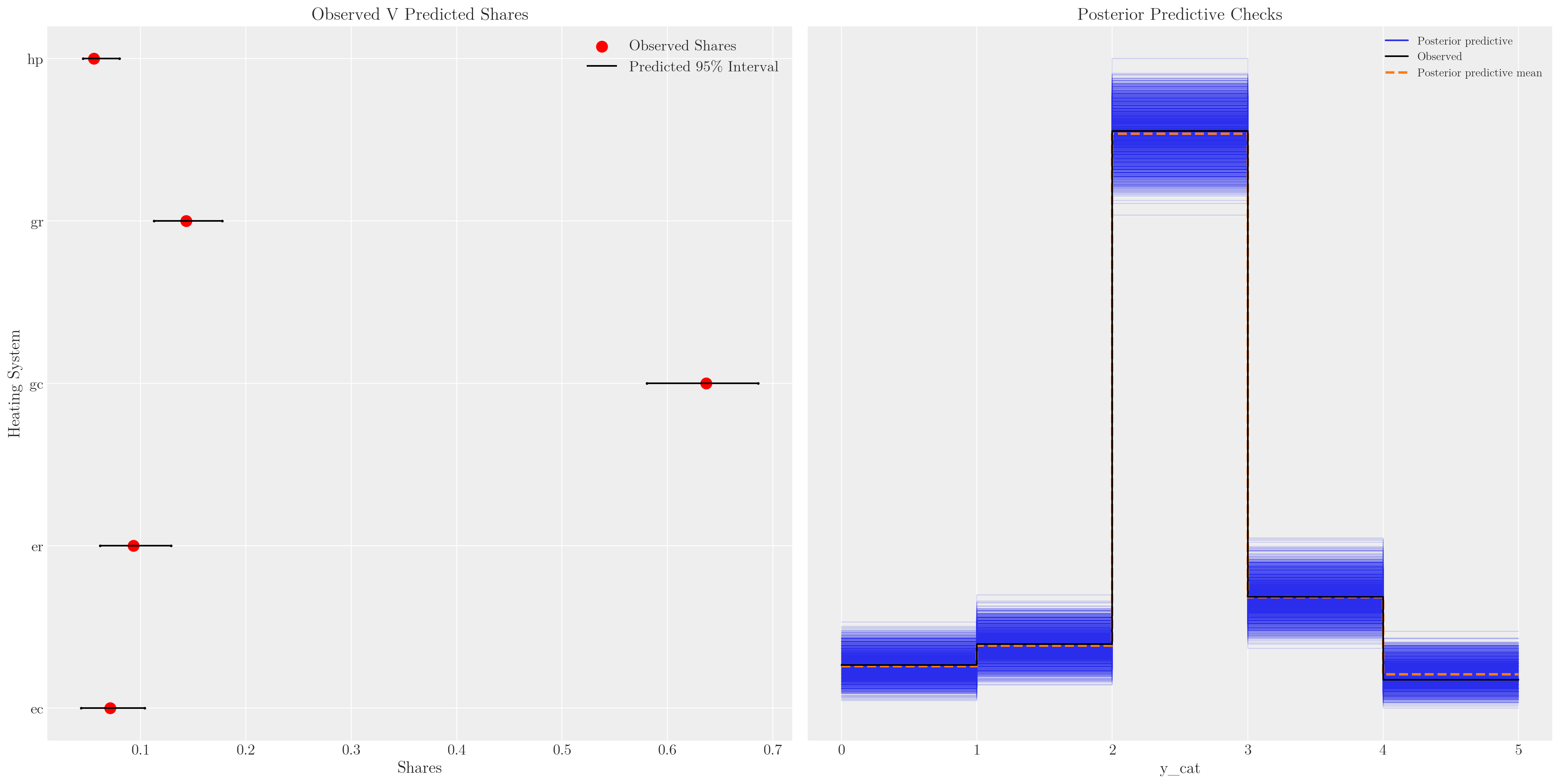
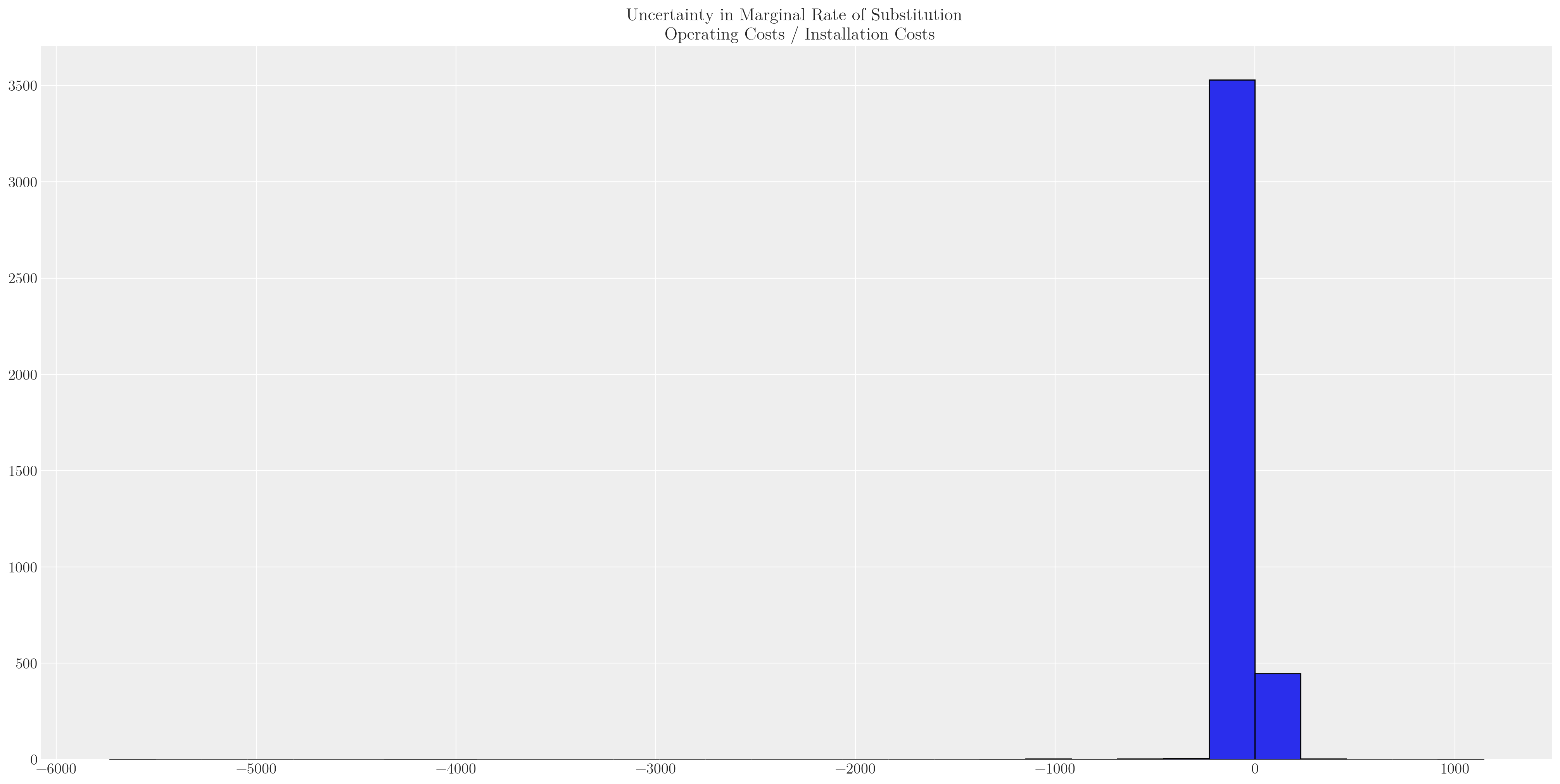
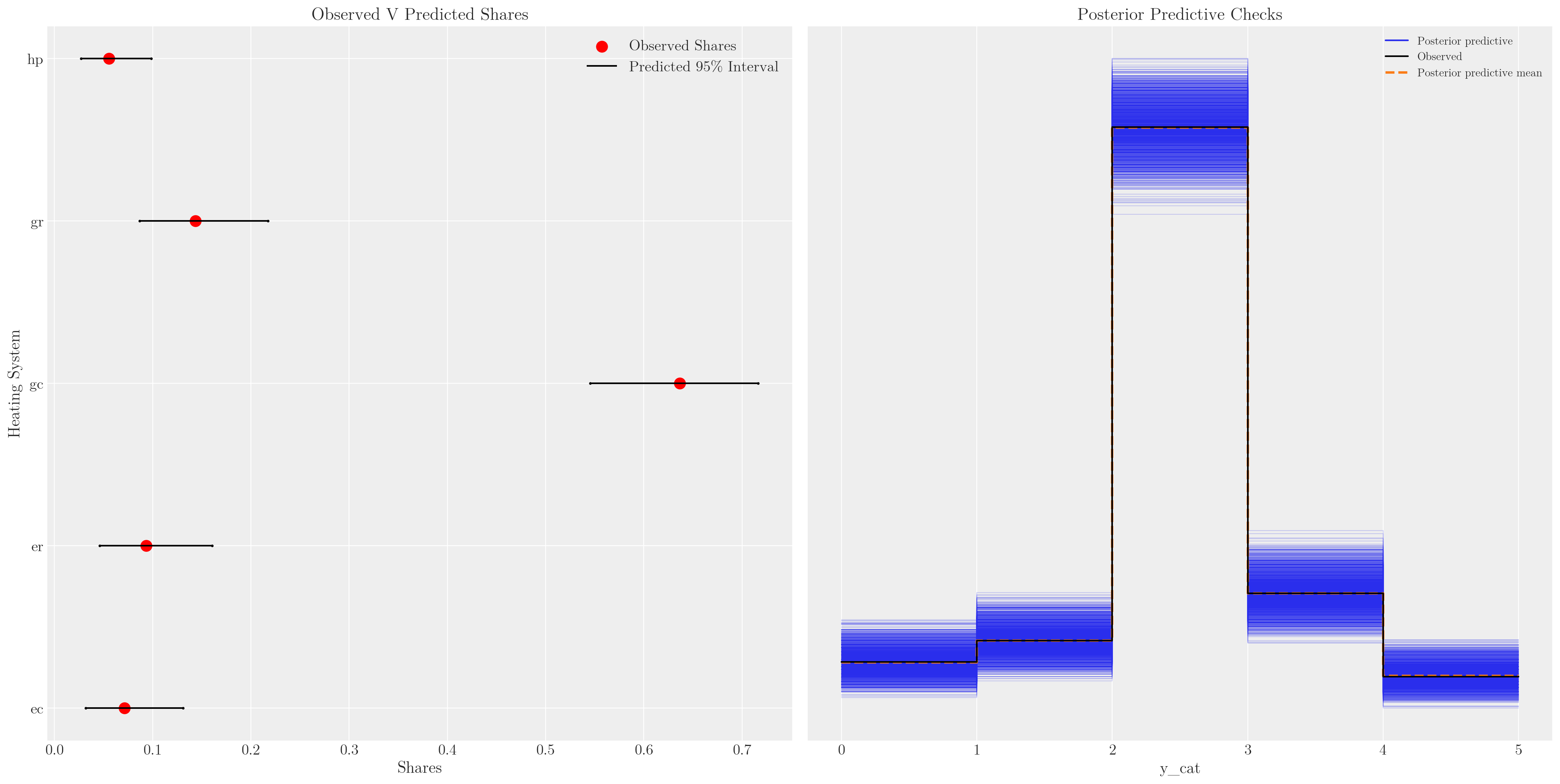
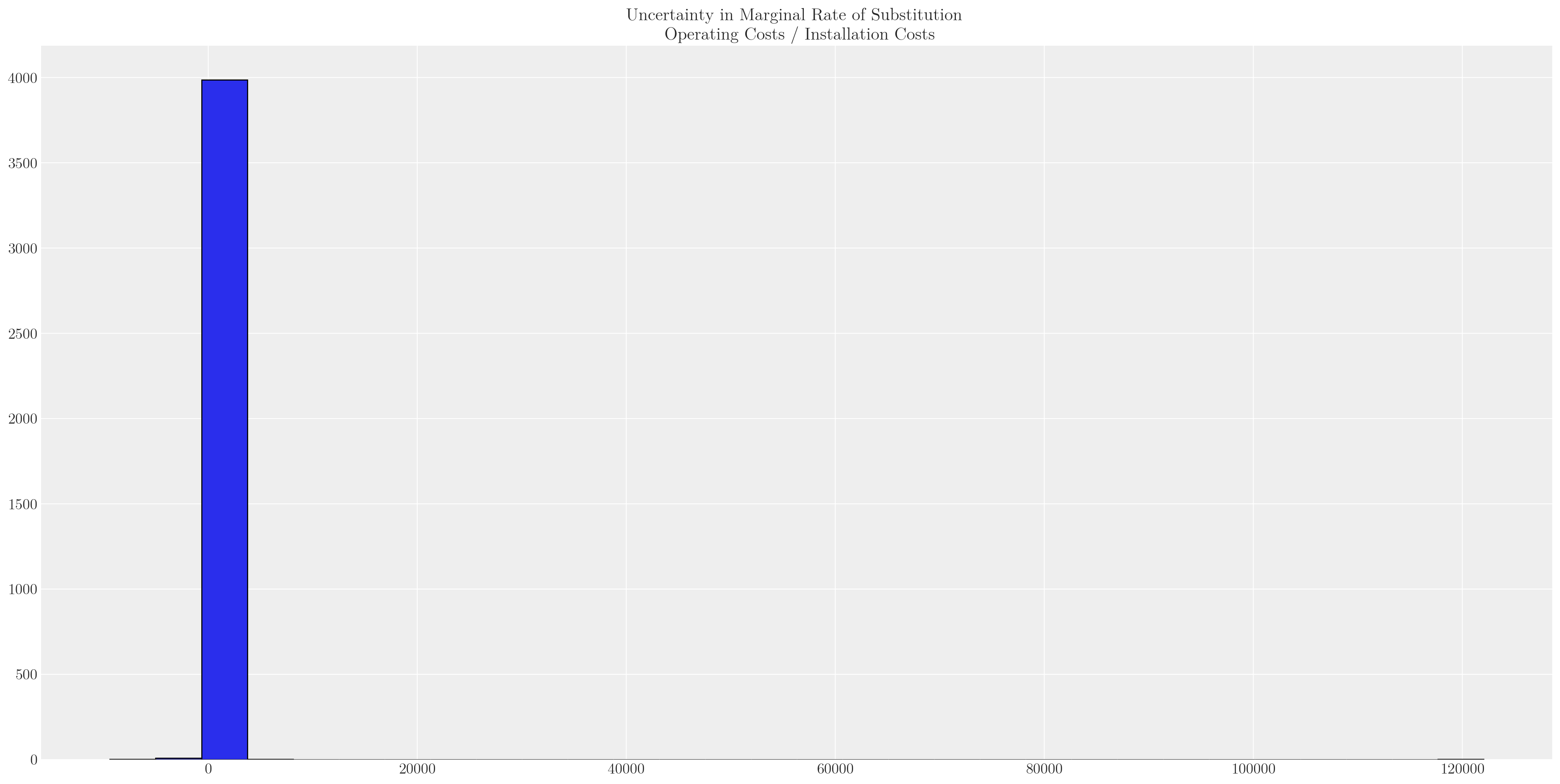
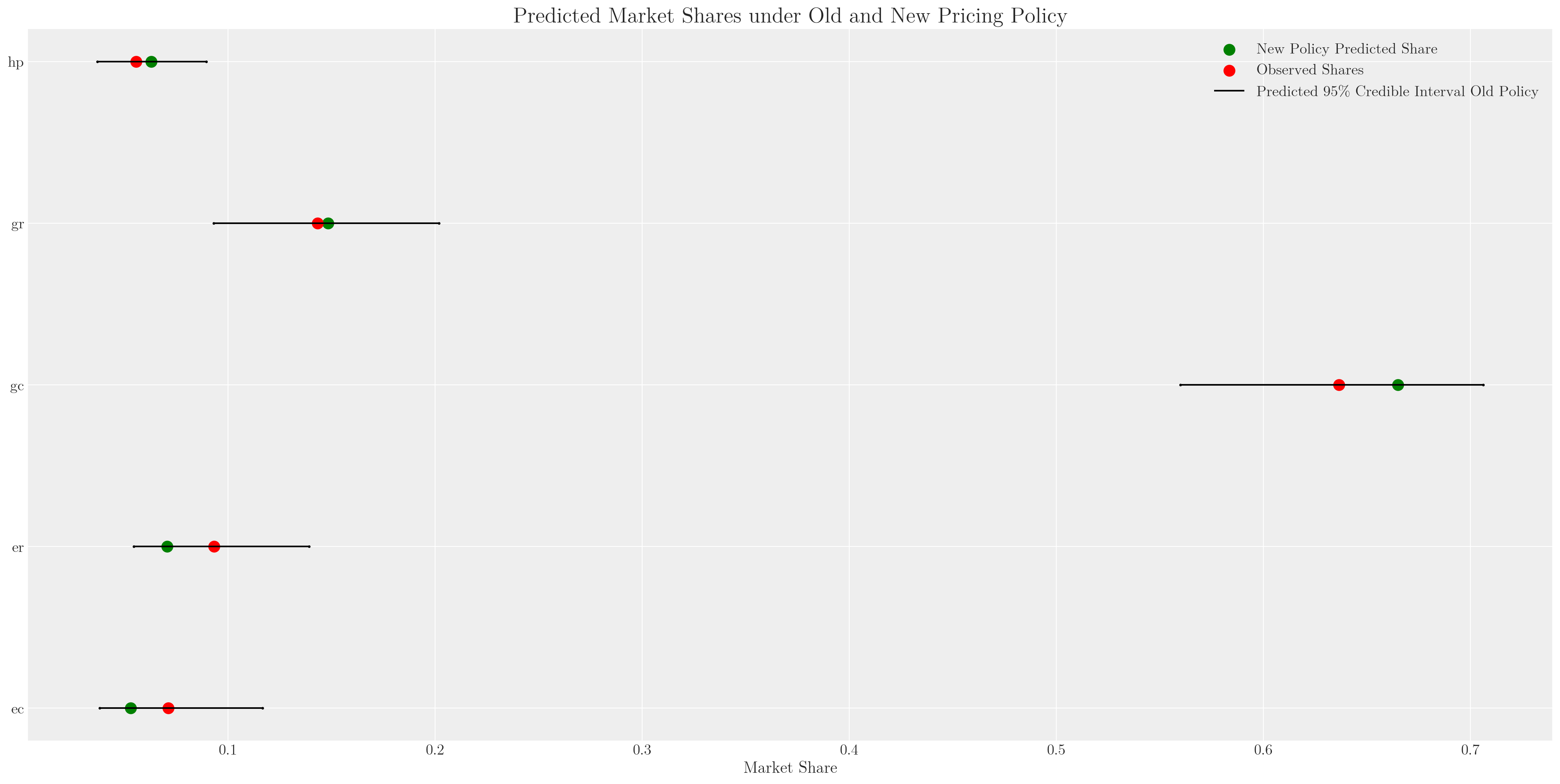
2 2 2 1 1 2 2 2 ... 2 2 1 2 2 2 2 2
array([2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 3, 4, 4, 1, 2, 0, 3,
2, 4, 2, 3, 2, 0, 0, 2, 2, 3, 3, 2, 2, 2, 3, 2, 2, 1, 2, 3, 2, 2,
2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 4, 3, 2, 4, 2, 2, 2, 2, 2, 2, 3, 2,
2, 2, 3, 2, 3, 2, 1, 4, 1, 2, 2, 2, 1, 3, 2, 2, 2, 4, 3, 2, 2, 2,
2, 2, 4, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 0, 2, 2, 2, 4, 2,
2, 2, 4, 1, 0, 2, 2, 2, 2, 2, 3, 1, 2, 2, 2, 2, 2, 2, 2, 3, 2, 3,
0, 3, 2, 3, 1, 0, 2, 2, 3, 2, 1, 4, 4, 3, 2, 3, 2, 2, 4, 3, 4, 2,
2, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 0, 2, 2, 2, 0, 1, 2, 2, 3, 2, 2,
2, 2, 3, 3, 1, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 4, 2, 2, 2, 2, 2, 2,
2, 2, 0, 2, 2, 3, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 3, 2, 0, 2, 2, 2, 2,
2, 3, 2, 2, 3, 2, 1, 0, 0, 4, 2, 2, 2, 2, 2, 1, 2, 3, 3, 3, 2, 2,
2, 3, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 3, 2, 2, 2, 4, 0, 2, 1,
3, 1, 2, 3, 2, 3, 0, 0, 4, 2, 2, 2, 2, 2, 0, 1, 2, 2, 2, 2, 2, 2,
2, 1, 1, 2, 1, 3, 1, 2, 4, 2, 2, 2, 2, 2, 4, 2, 2, 2, 2, 3, 2, 2,
2, 2, 1, 3, 2, 3, 2, 2, 2, 4, 4, 2, 3, 3, 3, 1, 2, 2, 2, 2, 2, 2,
4, 2, 2, 2, 4, 2, 0, 2, 3, 4, 2, 2, 2, 2, 2, 2, 2, 4, 0, 2, 1, 3,
0, 1, 2, 2, 2, 2, 2, 1, 2, 4, 3, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2,
2, 0, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 0, 3, 0, 2, 2, 3, 3, 2, 1, 0,
2, 1, 2, 2, 2, 2, 3, 0, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 0,
...
3, 2, 1, 2, 3, 2, 3, 3, 3, 2, 0, 2, 2, 3, 1, 2, 0, 1, 3, 2, 1, 0,
2, 3, 0, 0, 1, 3, 1, 2, 2, 2, 2, 4, 2, 1, 2, 2, 2, 2, 1, 2, 2, 3,
3, 2, 2, 2, 1, 2, 4, 2, 3, 0, 2, 1, 2, 1, 2, 2, 3, 2, 2, 2, 2, 3,
2, 2, 2, 2, 2, 1, 3, 2, 3, 2, 2, 2, 2, 3, 2, 2, 2, 1, 2, 0, 2, 2,
2, 3, 2, 3, 2, 0, 2, 3, 3, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 4, 3, 2,
3, 2, 2, 2, 2, 0, 2, 2, 3, 0, 2, 1, 1, 3, 2, 2, 2, 2, 3, 0, 3, 2,
2, 2, 2, 2, 2, 2, 2, 2, 4, 0, 4, 2, 1, 2, 1, 2, 2, 0, 2, 2, 1, 2,
3, 2, 3, 3, 2, 2, 4, 1, 2, 2, 2, 2, 4, 4, 1, 2, 2, 2, 1, 2, 1, 3,
3, 0, 4, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 3, 4, 2, 1, 1, 0,
2, 2, 2, 2, 1, 1, 3, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 3, 0, 2, 2, 2,
1, 2, 3, 4, 2, 1, 2, 3, 2, 3, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2,
2, 2, 2, 4, 2, 2, 2, 2, 2, 1, 2, 0, 2, 2, 3, 0, 3, 2, 2, 2, 3, 3,
2, 3, 2, 2, 2, 2, 2, 1, 4, 3, 2, 2, 4, 0, 3, 2, 1, 1, 2, 2, 2, 2,
0, 2, 2, 0, 2, 3, 2, 2, 2, 2, 3, 3, 2, 2, 2, 3, 2, 2, 2, 1, 4, 0,
2, 2, 2, 2, 2, 2, 2, 1, 4, 2, 2, 0, 2, 1, 2, 2, 0, 2, 3, 2, 2, 3,
3, 4, 2, 3, 2, 0, 2, 3, 2, 4, 3, 3, 2, 2, 2, 1, 2, 2, 1, 2, 2, 3,
0, 2, 2, 3, 2, 2, 1, 2, 3, 2, 2, 2, 2, 4, 1, 2, 2, 2, 2, 2, 3, 2,
1, 2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 3, 2, 3, 0, 2, 1, 2, 2, 2, 2, 2,
1, 1, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 3, 2, 2, 4, 4, 2, 2, 2,
1, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2])